Introduction
#define ROWS 256
#define COLUMNS 256
long long arr[ROWS][COLUMNS] = {0};
static void columnMajor(){
int rval = 0;
for(int i = 0; i < COLUMNS; i++){
for(int j = 0; j < ROWS; j++){
rval += arr[j][i];
}
}
}
static void rowMajor(){
int rval = 0;
for(int i = 0; i < ROWS; i++){
for(int j = 0; j < COLUMNS; j++){
rval += arr[i][j];
}
}
}
Take a look at the above code snippet. We have two void functions that simply sum all elements in a 2D long long array. At a glance they do the exact same thing, same time complexity, same iteration bounds.
But there’s one minor change that massively changes the performance between the two. This change takes advantage of an architectural feature of modern computers and the design/implementation of C++ arrays.
Analysis
We start by noting we create a 2D array of uint64_t’s with dimensions 256 columns and 256 rows. Recall that when we access a 2D array with known dimensions y rows and x columns, initialized as arr[y][x], some pointer arithmetic is done so that calling arr[m][n] is the same as calling the element arr[x * m + n]. In C++ (among other languages), 2D arrays are stored in contiguous memory blocks, where each segment of x elements represents a “row” and there are y “rows”.
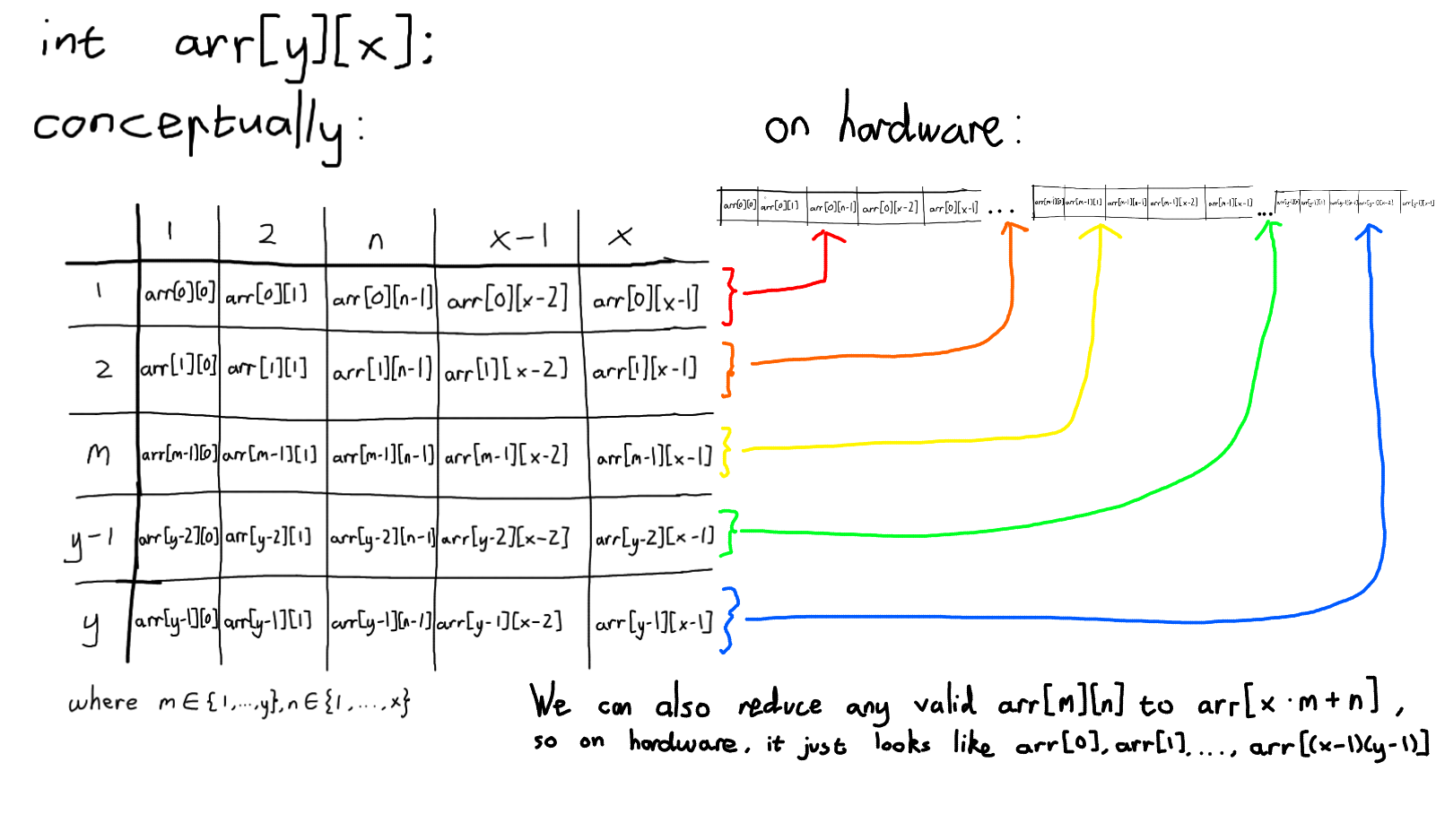
Following the array initialization, we define two functions that seemingly do the same thing. The key difference is that in one we iterate over row index, and then over the column index. In the other we iterate over the column index and then the row index. Functionally, these both just add all the elements in the array together, theres's the same number of array lookup operations and additiion operations, which means both have a time complexity of O(2 * ROWS * COLUMNS). They should have the same runtime.
Using Google Benchmark to verify, we actually see that the rowMajor function is more than twice as fast as it’s columnMajor counterpart.
------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------
columnMajor 112737 ns 112736 ns 6349
rowMajor 38386 ns 38377 ns 17709
But why??
Cache Line Utilization
Whenever an array access operation is performed, it is loaded in a cache line, which is then stored on the CPU’s cache. This is normally the 64 bytes on the aligned block containing the memory address we want to access. The size of the cache line is completely controlled by hardware, and does occasionally vary (like on Apple Silicon chips).
Looking back at array memory layouts, we can see that accessing an element corresponds to also accessing elements (mostly) on the same “row”. This is why rowMajor dominates columnMajor in runtime, some array data for some future additions are already in the cache. We can see this effect diminish as we make the sizeof the data smaller, where things start to even out, because more data is stored per cache line, so less cache lines need to be loaded for the entire 2D array to be summed.
Benchmarks
For all benchmarks:
- x axis represents the value of COLUMNS
- y axis represents the value of ROWS
- the value in a cell represents the number of iterations rowMajor completed divided by the number of iterations columnMajor completed
- THIS IS NOT COMPLETELY RIGOROUS and we should allow a 3% margain of error for a 95% confidence interval
- this is also my first time benchmarking so don’t roast me too hard
- github repo for benchmarks
Run on (10 X 24 MHz CPU s)
CPU Caches:
L1 Data 64 KiB
L1 Instruction 128 KiB
L2 Unified 4096 KiB (x10)
For uint64_t:
| 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | |
|---|---|---|---|---|---|---|---|---|
| 64 | 1.05 | 1.0 | 1.23 | 5.52 | 7.15 | 9.31 | 9.29 | 8.91 |
| 128 | 1.19 | 1.13 | 2.12 | 5.82 | 8.29 | 9.92 | 8.29 | 10.19 |
| 256 | 1.13 | 2.05 | 2.17 | 5.94 | 7.42 | 8.76 | 8.8 | 9.32 |
| 512 | 2.14 | 2.05 | 2.18 | 5.89 | 6.94 | 8.85 | 8.59 | 9.52 |
| 1024 | 2.14 | 2.05 | 2.22 | 5.76 | 7.06 | 9.03 | 9.02 | 10.15 |
| 2048 | 2.14 | 2.06 | 2.21 | 5.72 | 7.14 | 9.45 | 9.66 | 11.38 |
| 4096 | 2.13 | 2.02 | 2.2 | 5.9 | 7.7 | 9.52 | 10.68 | 13.03 |
| 8192 | 2.13 | 2.05 | 2.77 | 7.03 | 8.07 | 11.13 | 10.54 | 9.8 |
For uint32_t (4 bytes):
| 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | |
|---|---|---|---|---|---|---|---|---|
| 64 | 0.84 | 0.76 | 0.86 | 1.09 | 5.27 | 6.96 | 8.16 | 9.45 |
| 128 | 1.12 | 1.02 | 1.19 | 2.09 | 5.72 | 7.34 | 10.08 | 8.39 |
| 256 | 1.08 | 1.03 | 2.01 | 2.14 | 5.76 | 7.45 | 9.61 | 8.4 |
| 512 | 1.08 | 1.91 | 2.05 | 2.18 | 5.79 | 6.82 | 9.05 | 8.54 |
| 1024 | 2.08 | 1.91 | 2.04 | 2.19 | 5.72 | 6.86 | 8.88 | 8.74 |
| 2048 | 2.09 | 1.91 | 2.06 | 2.16 | 5.64 | 6.94 | 9.12 | 9.69 |
| 4096 | 2.1 | 1.92 | 2.03 | 2.19 | 5.79 | 7.41 | 9.71 | 9.78 |
| 8192 | 2.09 | 1.95 | 2.06 | 2.61 | 6.7 | 8.35 | 9.7 | 9.75 |
For uint16_t (2 bytes):
| 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | |
|---|---|---|---|---|---|---|---|---|
| 64 | 0.91 | 0.99 | 1.02 | 1.06 | 1.12 | 5.55 | 6.54 | 7.99 |
| 128 | 0.93 | 1.06 | 1.1 | 1.15 | 2.17 | 5.69 | 6.64 | 8.76 |
| 256 | 0.95 | 1.03 | 1.1 | 2.12 | 2.23 | 5.8 | 6.99 | 8.06 |
| 512 | 0.95 | 1.03 | 1.81 | 2.16 | 2.19 | 5.64 | 6.44 | 7.94 |
| 1024 | 0.96 | 1.77 | 1.99 | 2.21 | 2.43 | 5.51 | 6.56 | 8.31 |
| 2048 | 1.42 | 1.99 | 2.06 | 2.18 | 2.21 | 5.53 | 6.73 | 9.01 |
| 4096 | 1.59 | 2.07 | 2.02 | 2.15 | 2.3 | 6.02 | 7.41 | 9.6 |
| 8192 | 1.41 | 1.95 | 1.98 | 1.9 | 3.48 | 7.51 | 7.94 | 9.25 |
Interpretation
We can see a clear trend that as the size of an array increases, the greater the gains made by rowMajor access, as previously explained. We observe that generally, increasing columns leads to a larger performance difference for rowMajor access, which aligns with our previous theory, as we decrease the number of cache hits for columnMajor, whilst still retaining just about 100% for rowMajor. Furthermore, we see the falloff as we approach really large array sizes, as both functions start to make more array access operations and hence the amount of data retrievals from RAM increase. This diminishes the advantage that rowMajor’s cache hits have, as it will still need to perform I/O which contributes more to its runtime than the increment.
However, this doesn’t explain the case for uint16_t and even more so uint32_t, where it seems that in some cases, columnMajor access is actually faster than rowMajor access. I theorise this could be up to something to do with SIMD or optimized operations for these data types, or it could be any other number of things I am not aware of. This is an interesting finding that I will try to get to the bottom of some other time (with a post of course!).
Implication
When doing data intensive operations, one should be wary of row vs column major access, depending on programming language, implementation of data structures and even machine architecture. I am sure that columnMajor only beats rowMajor in smaller array sizes because of some architectural feature of the cache or SIMD or array stride or any other number of things that I don’t know enough about.
The process of benchmarking was also quite interesting to me, being able to quantify performance differences empirically instead of theoretically, and it’s definetely something I hope to do more of with future projects.
As always, my contact info is listed at chenrz.com/about/.